Infrastructure as Code is genuinely game-changing. When approached correctly, that is. Within the Infrastructure as Code world, Terraform is one of the most popular infrastructure automation tools, praised for its flexibility and portability.
Data Sources, a key Terraform feature, brings its portability to a whole new level, enabling you to get information about external resources and use them in your Terraform resources.
This article provides an in-depth overview of Data Sources and how to take full advantage of these to manage your Infrastructure as Code more efficiently.

What are the data sources in Terraform?
Data sources allow data to be fetched or computed elsewhere in Terraform configuration.
Many Terraform users are using local and global variables to send data to Terraform configuration. While this is a legitimate approach, you can also leverage Terraform data sources to reduce the need to send parameters to your Terraform code.
Data sources allow a Terraform configuration to use the information defined outside Terraform or in a different Terraform project.
Access information outside of Terraform — If you want to call external APIs available as data sources through a provider, you can access them inside your Terraform configuration.
- Access information in a different Terraform Configuration — If you want to access information from another Terraform source, you can also use data sources.
A data source is accessed via a special kind known as a data resource, which is declared using a data block.
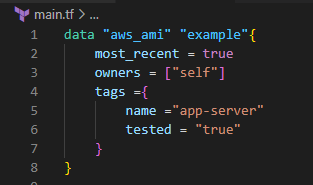


A data block requests that Terraform read from a given data source (“aws_ami”) and export the result under the given local name (“example”).
This refers to this resource elsewhere in the same Terraform module. However, it has no significance outside of the scope of a module.
Key differences between Resource and Data Source
Terraform Resource: Resources are the essential element in the terraform language. Each resource block contains one or more infrastructure objects, such as virtual networks, compute instances, or higher-level components, such as DNS records.
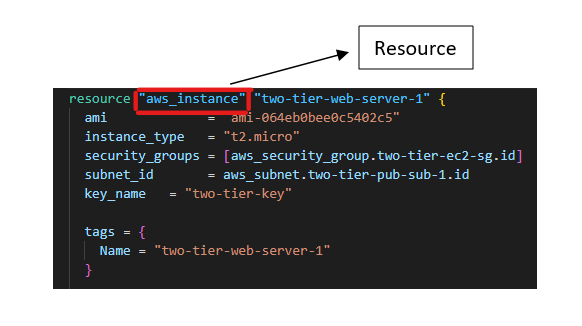
While a resource can be created, updated, and destroyed, data sources need NOT be created/updated/destroyed. They are only used to read specific data and make it available to the other resources in the Terraform configuration.
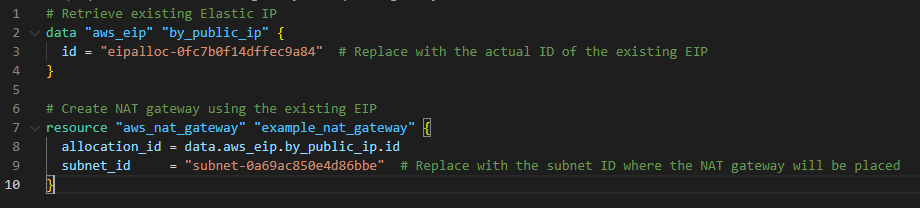
If you need to read from the data source elsewhere in the Terraform configuration, you should define a name (E.g., “by_public_ip”). That’s all.
This example reads the id of the EIP data source and using that EIP creates a NAT gateway.

How Terraform Data sources work
Here is an example process of how a Terraform data source works:
- Define the data source in the Terraform configuration file.
- Terraform reads the configuration file and detects the data source block.
- Terraform calls the provider’s API and sends the required configuration values.
- The provider responds with the requested data.
- Terraform parses the response and stores the data in memory.
- Terraform uses the retrieved data to create or update resources that depend on it.
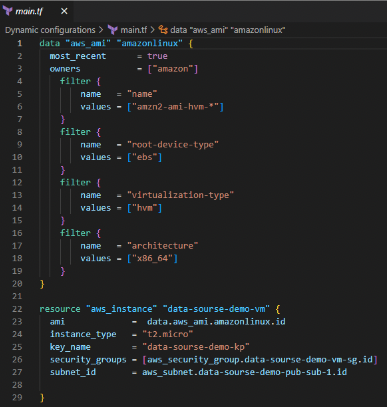
Look at the following example of creating a data source to fetch the latest AMI ID:
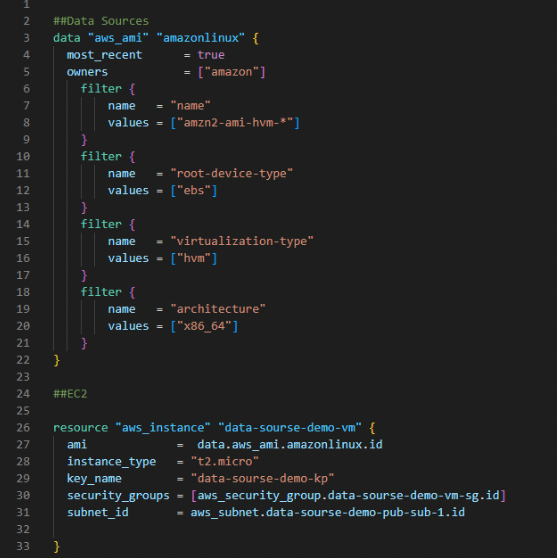
In most cases, we hard-code respective AMI IDs. But in this example, we use the data sources concept and get the AMI ID automatically.
Steps
- Create a data block for aws_ami
- The local name is amazonlinux, and The data source type is aws_ami.
- We set the value of “most recent” to “true.” It means you will always get the latest one.
- The next up is the owners. Let’s declare that “Amazon” owns this respective AMI.
- Now let’s write filters.
The first filter is the name and value “amzn2-ami-hvm-*,” which is nothing but the AMI name.
The following filter is the root device and virtualization types, and the architecture and value are “x86_64”. So we have created the data source.
So instead of manually entering the ami value, we use data sources to automatically update the most recent ami for the EC2.
7 Ways to Use Terraform Data Sources for a Better Infrastructure as Code
1. Access External APIs
Terraform data sources help you fetch data from external APIs and use them to build your infrastructure. All the configurations are done automatically using this feature, reducing human errors in hard coding and increasing its reusability as you can use external APIs in different terraform configurations.
Another advantage of using this feature is that you can manage sensitive information without exposing it to terraform files.
Look at the following example of an existing EC2 instance that doesn’t have an elastic IP. You can use data sources to fetch data from that EC2 instance and attach an EIP for that EC2.
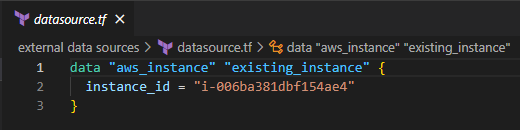
The below screenshot shows how to add a data source to reference the existing elastic IP.
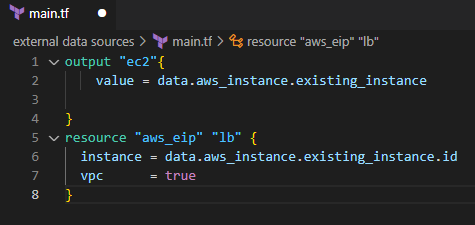
Finally, you can run Terraform apply to apply changes to the resources. Now you should see the Elastic IP is applied to the EC2 instance.

2. Use Remote State
Terraform’s remote state feature allows you to store your Terraform state in a remote location, like an S3 bucket or a database.
Data sources can be used to fetch data from your remote state and use it to configure your resources, enabling you to share data across different Terraform projects, making managing and updating your infrastructure easier.
However, this is not a best practice as the remote state file can contain sensitive data you might not want to share with other infrastructure stacks.
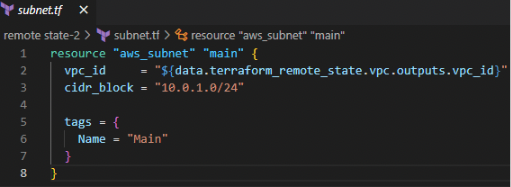
Time to get our hands dirty. Let’s create a VPC and store the state file in an S3 bucket. Then let’s create a subnet in that VPC referencing the VPC ID.
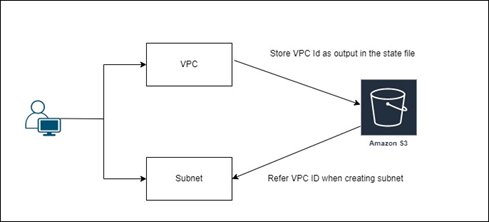
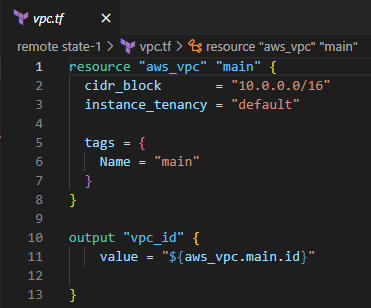
First, Create a VPC with a given CIDR range.
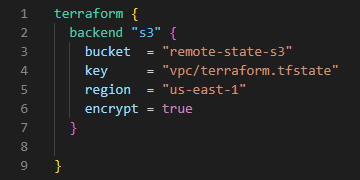
Then let’s store the state file in an S3 bucket called remote-state-s3.
Next, use that state file to create a subnet in a separate terraform configuration file.
This is where you can use the data source “terraform_remote_state” which refers to a remote state file. Then, let’s create the subnet using that data source.
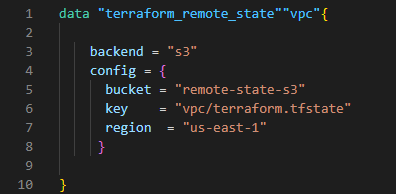
In the below screenshot, vpc_id is referred from the data source.
3. Manage Secrets
Data sources can fetch sensitive data, like passwords or API keys, from a secure storage system like Vault or AWS Secrets Manager.
This means you can keep your sensitive data separate from your Terraform code and avoid storing secrets in plain text. Instead, you can fetch the secrets as data sources and use them to configure your infrastructure.
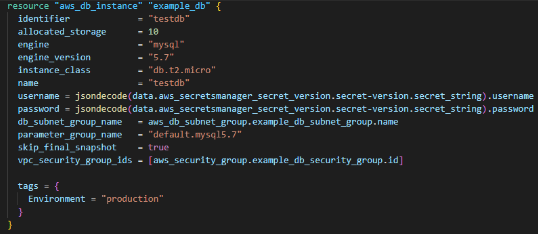
In this example, let’s get the security credentials (username, password) from AWS secret manager and create an RDS instance.
AWS Secret stores the username and password, and in this part of the code, it fetches the credentials from the AWS secret and puts it into the “aws_secretsmanager_secret_version” data field.
Here in the secret_id phase, you have to put the id of the AWS secret manager.

This is an example of creating an RDS. When making this RDS, there are two phases in this resource session: username and password. So, in those two sections, you must define the data source mentioned in the above figure. So, what it does is it takes the credentials from the existing secret manager and puts it into username and password fields in “aws_db_instance” section.
4. Create Dynamic Configurations
Using data sources allows you to configure the infrastructure more dynamically. So, if you run your EC2 instances with the latest AMI from Amazon, and you don’t want to manually change the image id in your Terraform code every time AWS releases a new version, Terraform data sources can help.
In this case, Terraform data sources give dynamic configurations, meaning you can retrieve the most recent value of AWS AMIs when configuring the “terraform apply” command.

5. Manage Configuration Drift
In Terraform, “Configuration Drift” refers to the situation where the current state of a resource reported by the provider (e.g., AWS) no longer matches the state defined in the Terraform configuration. This can occur when someone manually changes a resource outside of Terraform without Terraform being aware of those changes.
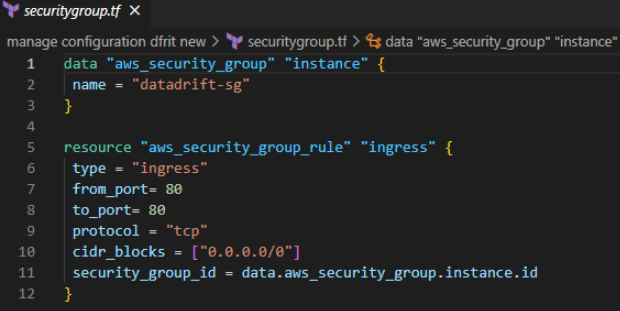
Let’s say you have a Terraform configuration that defines an AWS security group(“datadrift-sg”) with an inbound rule allowing SSH traffic from a specific IP address. When you run Terraform Apply, Terraform will create the security group with the specified control.
Later, someone logs into the AWS console and manually modifies the security group to add another inbound rule allowing SSH traffic from a different IP address. If you were to run ‘terraform apply’ again after that, Terraform would see that the current state of the security group no longer matches the state it expects based on the configuration. This is connection drift.
To resolve this, you could use Terraform’s state reconciliation feature to update the state of the security group in the Terraform state file to match the current state in AWS. Alternatively, you could modify the Terraform configuration to include the new inbound rule and then run Terraform apply to update the security group to the desired state.
It’s generally best to refrain from manual changes to resources managed by Terraform, as this can lead to connection drift and make it more difficult to manage infrastructure using Terraform.
6. Create Resource Dependencies
Terraform allows you to specify dependencies between resources, ensuring that resources are created in the correct order. Data sources can be used to develop resource dependencies by fetching data from one resource and using it to configure another resource.
In Terraform, you can define data dependencies using the depends_on argument in a data source block. This argument allows you to specify that a data source depends on other resources and must be retrieved after those resources have been created or updated.
In this example, we start by defining a variable named vpc_id. This variable will accept the VPC ID as input when executing Terraform commands. By using variables, you can make your configuration more flexible and reusable.
This is the existing VPC.
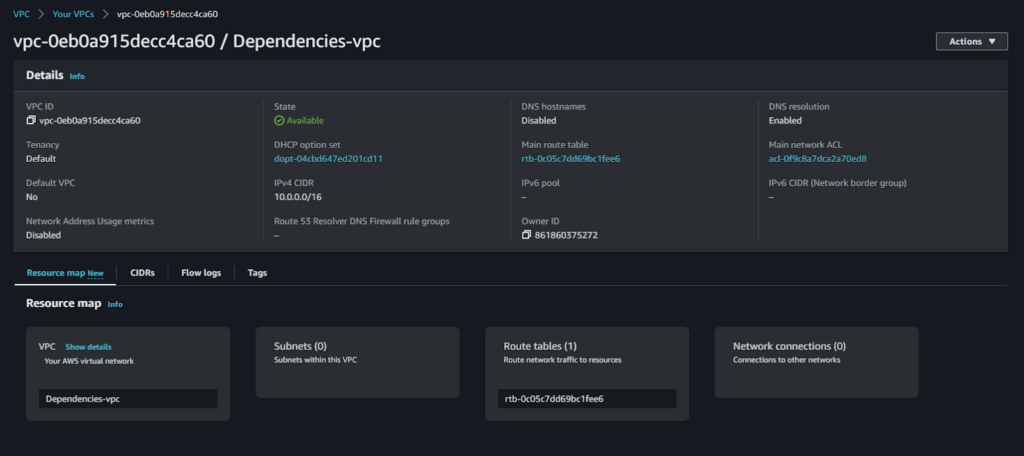
The aws_vpc data source block is defined with the name Dependencies-vpc. It uses the id attribute and references the var.vpc_id variable to fetch the necessary data for the specified VPC ID. This data source fetches information such as the VPC’s CIDR block.
Next, we create the aws_subnet resource named subnet. The vpc_id attribute of this resource is set to data.aws_vpc.selected.id, which ensures that the subnet is associated with the selected VPC.
Additionally, the cidr_block attribute of the aws_subnet resource uses the cidrsubnet function to derive the subnet CIDR block based on the parent VPC’s CIDR block. The cidrsubnet function allows you to create subnets with distinct CIDR blocks within the VPC. So that subnet depends on the existing VPC (Refer to the below terraform code).
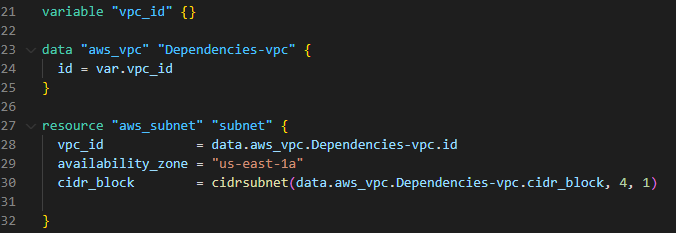
This is the resource map after the creation of the subnet.
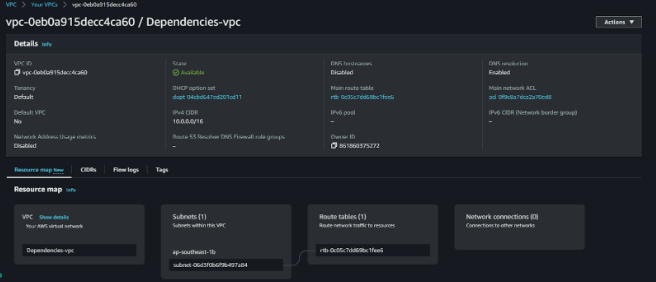
By setting up this dependency between the aws_vpc data source and the aws_subnet resource, Terraform will confirm that the VPC is created or updated before creating the subnet. This ensures that the subnet is associated with an existing VPC and avoids errors that could occur if the VPC does not exist or is not yet created.
7. Validate Input Data
Terraform data sources can be used to validate input data before using it to configure your infrastructure.
In this example, the user provided the name of an existing security group. So, in the local field, define the length of the security group name. Before using the aws_instance resource, this validation step guarantees that the security group name is not empty.
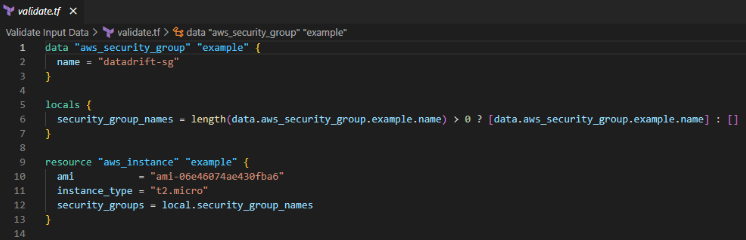
When you type “terraform validate,” if it’s validated, it provides this kind of output.

Control Your Cloud Infrastructure
Terraform’s data sources is a powerful tool that can be used to fetch data from external sources and assist in configuring your infrastructure.
By leveraging data sources, you can create more flexible and adaptable infrastructure configurations that can easily integrate with external services and share data across different projects.
However, using data sources in your Terraform Code is only the first step in managing your cloud right, and in order to really control your cloud environments you will need a platform that helps you:
- Reach a 99% Terraform coverage on your cloud resources
- Enforce policies before deployment
- Identify drifts and deviations
- Share compliant infrastructure blueprints with other teams
Which is exactly what the ControlMonkey platform does.
To learn more about our Terraform Operations platform, click here.